

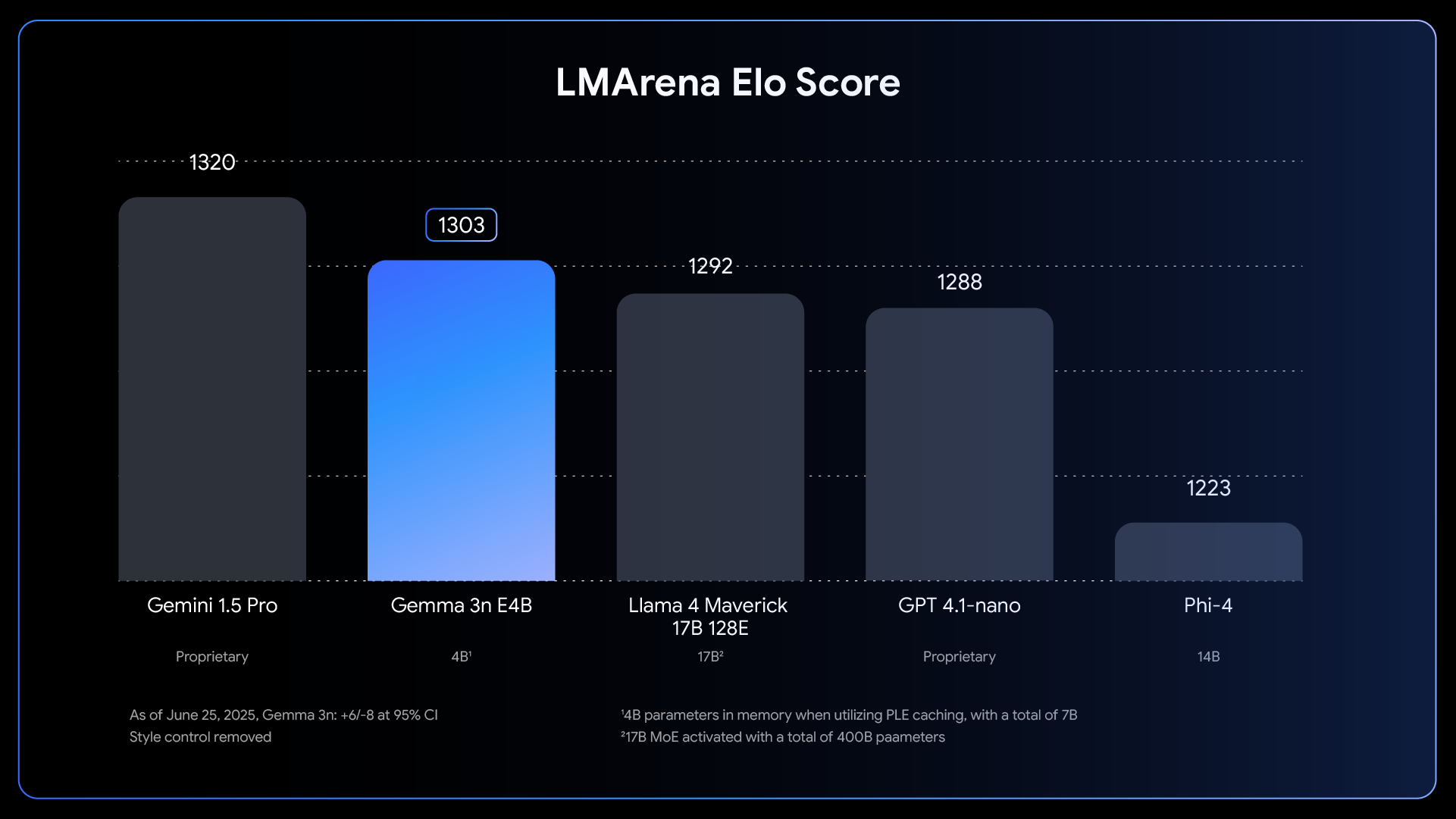
Model Gemma pertama diluncurkan awal tahun lalu dan sejak saat itu telah berkembang menjadi ekosistem Gemmaverse dengan lebih dari 160 juta download kolektif. Ekosistem ini mencakup rangkaian lebih dari selusin model khusus untuk segala hal, mulai dari pengamanan hingga aplikasi medis, dan yang paling menginspirasi, inovasi tak terhitung dari komunitas. Dari inovator, seperti Roboflow yang membangun computer vision perusahaan, hingga Institute of Science Tokyo yang menciptakan varian Gemma Jepang dengan kemampuan tinggi, karya Anda telah menunjukkan kepada kami jalan ke depan.
Melanjutkan momentum yang luar biasa ini, kami sangat senang bisa mengumumkan perilisan penuh Gemma 3n. Meskipun pratinjau bulan lalu memberikan gambaran sekilas, hari ini kami membuka kekuatan penuh dari arsitektur yang mengutamakan seluler ini. Gemma 3n dirancang untuk komunitas developer yang telah membantu membentuk Gemma. Ia didukung dengan alat favorit Anda termasuk Hugging Face Transformers, llama.cpp, Google AI Edge, Ollama, MLX, dan banyak lagi, memungkinkan Anda menyempurnakan dan menerapkan untuk aplikasi di perangkat tertentu dengan mudah. Postingan ini adalah pendalaman dari sisi developer: kami akan menjelajahi beberapa inovasi di balik Gemma 3n, berbagi hasil tolok ukur baru, dan menunjukkan kepada Anda cara untuk mulai membangun hari ini.
Gemma 3n merepresentasikan kemajuan besar untuk AI di perangkat, menghadirkan kemampuan multimodal yang kuat ke perangkat edge dengan performa yang sebelumnya hanya terlihat pada model frontier berbasis cloud tahun lalu.
Link to Youtube Video (visible only when JS is disabled)
Mencapai lompatan dalam performa di perangkat ini membutuhkan pemikiran ulang model dari dasar. Fondasinya adalah arsitektur unik Gemma 3n yang mengutamakan seluler, dan semuanya dimulai dengan MatFormer.
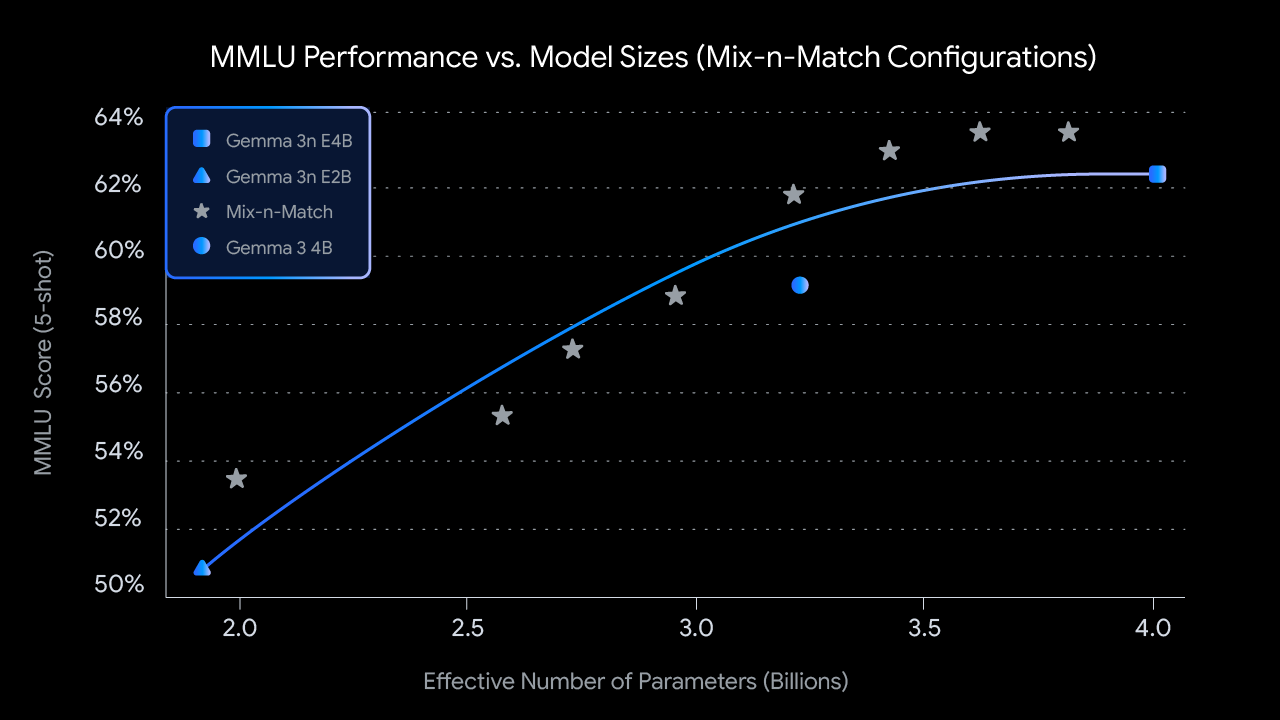
Inti dari Gemma 3n adalah arsitektur MatFormer (🪆Matryoshka Transformer), nested transformer baru yang dibangun untuk inferensi elastis. Analoginya seperti boneka Matryoshka: model yang lebih besar berisi versi dirinya dengan ukuran lebih kecil yang berfungsi penuh. Pendekatan ini memperluas konsep Matryoshka Representation Learning dari sekadar penyematan ke semua komponen transformer.

Selama pelatihan MatFormer untuk model parameter efektif 4B (E4B), sub-model parameter efektif 2B (E2B) secara simultan dioptimalkan di dalamnya, seperti yang ditunjukkan pada gambar di atas. Hal ini memberikan developer dua kemampuan yang kuat dan kasus penggunaan saat ini:
1: Model yang sudah diekstraksi: Anda bisa langsung mendownload dan menggunakan model E4B utama untuk kemampuan tertinggi, atau sub-model E2B standalone yang sudah kami ekstraksi untuk Anda, yang menawarkan inferensi hingga 2x lebih cepat.
2: Ukuran khusus dengan Mix-n-Match: Untuk kontrol yang lebih granular yang disesuaikan dengan batasan hardware tertentu, Anda bisa menciptakan spektrum model berukuran khusus antara E2B dan E4B menggunakan metode yang kami sebut Mix-n-Match. Teknik ini memungkinkan Anda untuk secara tepat mengiris parameter model E4B, terutama dengan menyesuaikan dimensi tersembunyi jaringan feed forward per lapisan (dari 8192 hingga 16384) dan secara selektif melewatkan beberapa lapisan. Kami merilis MatFormer Lab, sebuah alat yang menunjukkan cara mengambil model optimal ini, yang diidentifikasi dengan mengevaluasi berbagai setelan pada tolok ukur seperti MMLU.
Ke depannya, arsitektur MatFormer juga membuka jalan untuk eksekusi elastis. Meskipun bukan bagian dari implementasi yang diluncurkan hari ini, kemampuan ini memungkinkan satu model E4B yang diterapkan untuk beralih secara dinamis antara jalur inferensi E4B dan E2B dengan cepat, memungkinkan pengoptimalan performa dan penggunaan memori secara real-time berdasarkan tugas dan muatan perangkat saat ini.
Model Gemma 3n menggabungkan Per-Layer Embeddings (PLE). Inovasi ini dirancang untuk deployment di perangkat karena secara dramatis meningkatkan kualitas model tanpa meningkatkan jejak memori berkecepatan tinggi yang diperlukan pada akselerator (GPU/TPU) perangkat Anda.
Meskipun model Gemma 3n E2B dan E4B memiliki jumlah parameter total 5B dan 8B, PLE memungkinkan sebagian besar parameter ini (sematan yang terkait dengan setiap lapisan) dimuat dan dikomputasi secara efisien pada CPU. Ini berarti hanya bobot transformer inti (sekitar 2B untuk E2B dan 4B untuk E4B) yang perlu ditempatkan di memori akselerator (VRAM) yang biasanya lebih terbatas.

Memproses input panjang, seperti urutan yang berasal dari streaming video dan audio, sangatlah penting untuk banyak aplikasi multimodal lanjutan di perangkat. Gemma 3n memperkenalkan KV Cache Sharing, sebuah fitur yang dirancang untuk secara signifikan mempercepat waktu ke token pertama untuk aplikasi respons streaming.
KV Cache Sharing mengoptimalkan cara model menangani tahap pemrosesan input awal (sering disebut tahap “prefill”). Kunci dan nilai lapisan tengah dari perhatian lokal dan global secara langsung dibagikan ke semua lapisan teratas, memberikan peningkatan 2x pada performa prefill dibandingkan Gemma 3 4B. Ini berarti model dapat menyerap dan memahami urutan prompt yang panjang dengan lebih cepat daripada sebelumnya.
Gemma 3n menggunakan enkoder audio canggih yang berbasis Universal Speech Model (USM). Enkoder menghasilkan token untuk setiap 160ms audio (sekitar 6 token per detik), yang kemudian diintegrasikan sebagai input ke model bahasa, memberikan representasi granular konteks suara.
Kemampuan audio terintegrasi ini membuka fitur utama untuk pengembangan di perangkat, termasuk:
Kami mengamati hasil AST yang sangat kuat untuk terjemahan antara bahasa Inggris dan Spanyol, Prancis, Italia, dan Portugis, yang menawarkan potensi besar bagi developer yang menargetkan aplikasi dalam bahasa-bahasa tersebut. Untuk tugas seperti penerjemahan ucapan, memanfaatkan prompting Chain-of-Thought dapat meningkatkan hasil secara signifikan. Berikut adalah contohnya:
<bos><start_of_turn>user
Transcribe the following speech segment in Spanish, then translate it into English:
<start_of_audio><end_of_turn>
<start_of_turn>modelPada waktu peluncuran, enkoder Gemma 3n diimplementasikan untuk memproses klip audio hingga 30 detik. Namun, ini bukan batasan fundamental. Enkoder audio yang mendasarinya adalah enkoder streaming, yang mampu memproses audio yang panjangnya berubah-ubah dengan pelatihan audio tambahan berformat panjang. Implementasi lanjutan akan membuka aplikasi streaming panjang dengan latensi rendah.
Selain kemampuan audio terintegrasi, Gemma 3n memiliki fitur enkoder visi baru yang sangat efisien, MobileNet-V5-300M, memberikan performa tercanggih untuk tugas multimodal di perangkat edge.
Didesain untuk fleksibilitas dan kekuatan pada hardware yang terbatas, MobileNet-V5 memberikan developer:
Level performa ini dicapai dengan beberapa inovasi arsitektur, termasuk:
Memanfaatkan desain arsitektur baru dan teknik distilasi lanjutan, MobileNet-V5-300M secara substansial mengungguli SoViT dasar di Gemma 3 (dilatih dengan SigLip, tanpa distilasi). Di TPU Google Pixel Edge, ia memberikan kecepatan 13x dengan kuantisasi (6,5x tanpa kuantisasi), membutuhkan parameter 46% lebih sedikit, dan memiliki jejak memori 4x lebih kecil, sekaligus memberikan akurasi yang jauh lebih tinggi pada tugas visi-bahasa
Kami sangat antusias untuk membagikan lebih banyak informasi tentang pekerjaan di balik model ini. Nantikan laporan teknis MobileNet-V5 mendatang, yang akan membahas lebih dalam tentang arsitektur model, strategi penskalaan data, dan teknik distilasi lanjutan.
Membuat Gemma 3n dapat diakses sejak hari pertama telah menjadi prioritas kami. Kami bangga bisa bermitra dengan banyak developer open source yang luar biasa untuk memastikan dukungan yang luas di seluruh alat dan platform populer, termasuk kontribusi dari tim di balik AMD, Axolotl, Docker, Hugging Face, llama.cpp, LMStudio, MLX, NVIDIA, Ollama, RedHat, SGLang, Unsloth, dan vLLM.
Namun ekosistem ini hanyalah permulaan. Kekuatan sebenarnya teknologi ini terletak pada aplikasi yang akan Anda buat dengannya. Itulah mengapa kami meluncurkan Gemma 3n Impact Challenge. Misi Anda: menggunakan kemampuan Gemma 3n yang unik di perangkat, offline, dan multimodal untuk membangun produk demi dunia yang lebih baik. Dengan hadiah sebesar $150.000, kami mencari cerita video yang menarik dan demo yang punya faktor “wow” yang menunjukkan dampak di dunia nyata. Bergabunglah dengan tantangan ini dan bantu membangun masa depan yang lebih baik.
Siap menjelajahi potensi Gemma 3n hari ini? Begini caranya:

Build with Veo 3, now available in the Gemini API
Simplify your Agent "vibe building" flow with ADK and Gemini CLI
Inovasi multibahasa dalam LLM: Bagaimana model terbuka membantu membuka komunikasi global

Unlock Gemini’s reasoning: A step-by-step guide to logprobs on Vertex AI

T5Gemma: Koleksi model Gemma baru berbasis encoder-decoder