

El primer modelo de Gemma se lanzó a principios del año pasado y desde entonces se ha convertido en un próspero Gemmaverse de más de 160 millones de descargas colectivas. Este ecosistema incluye nuestra familia de más de una docena de modelos especializados para todo, desde la protección hasta las aplicaciones médicas y, lo que es más inspirador, las innumerables innovaciones de la comunidad. Desde innovadores como Roboflow, que construye visión artificial empresarial, hasta el Instituto de Ciencias de Tokio, que crea variantes de Gemma japonesas altamente capaces, su trabajo nos muestra el camino a seguir.
Aprovechando este increíble impulso, nos complace anunciar el lanzamiento completo de Gemma 3n. Si bien la versión preliminar del mes pasado ya nos dio una idea, hoy revela toda la potencia de esta arquitectura que prioriza los dispositivos móviles. Gemma 3n está diseñado para la comunidad de desarrolladores que ayudó a dar forma a Gemma. Es compatible con tus herramientas favoritas, como Hugging Face Transformers, llama.cpp, Google AI Edge, Ollama, MLX y muchas otras, lo que te permite implementar y ajustar tus aplicaciones específicas para dispositivos con facilidad. En esta publicación, haremos un análisis profundo para desarrolladores: exploraremos algunas de las innovaciones detrás de Gemma 3n, compartiremos nuevos resultados de referencia y te mostraremos cómo comenzar a crear hoy.
Gemma 3n representa un gran avance para la IA en dispositivos, ya que brinda potentes funciones multimodales a dispositivos perimetrales con un rendimiento que anteriormente solo se veía en los modelos de frontera basados en la nube del año pasado.
Link to Youtube Video (visible only when JS is disabled)
Lograr este salto en el rendimiento del dispositivo requirió repensar el modelo desde cero. La base es la arquitectura única de Gemma 3n que prioriza los dispositivos móviles, y todo comienza con MatFormer.
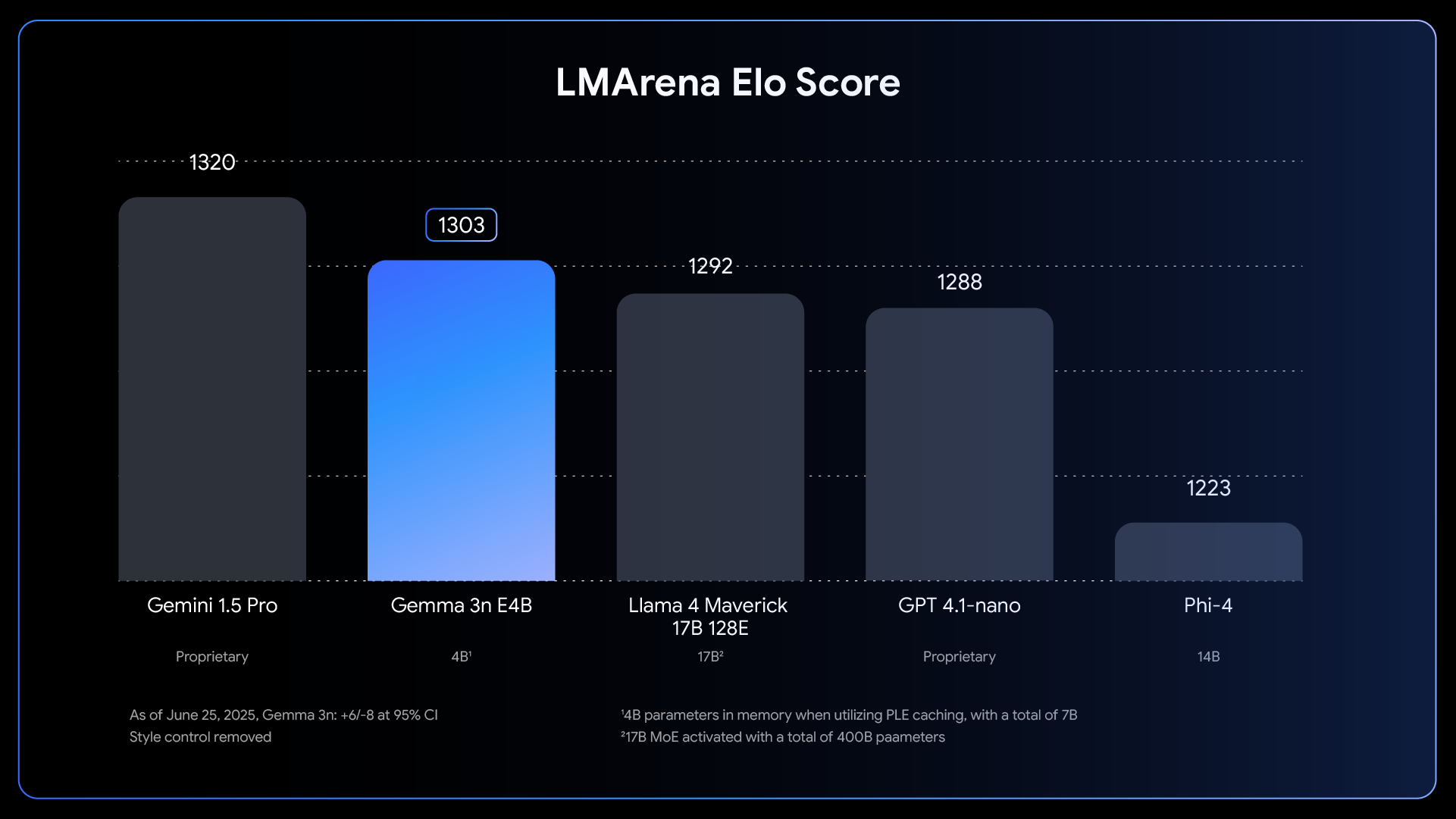
En el núcleo de Gemma 3n, se encuentra la arquitectura MatFormer (🪆 Matryoshka Transformer), un novedoso transformador anidado creado para la inferencia elástica. Piensa que es como las muñecas rusas: un modelo más grande contiene versiones más pequeñas y completamente funcionales de sí mismo. Este enfoque extiende el concepto de Matryoshka Representation Learning desde solo inserciones hasta todos los componentes del transformador.

Durante el entrenamiento de MatFormer del modelo de parámetro efectivo 4B (E4B), se optimiza simultáneamente un submodelo de parámetro efectivo 2B (E2B) dentro de él, como se muestra en la imagen anterior. Esto proporciona a los desarrolladores dos potentes funciones y casos de uso actuales:
1: Modelos extraídos previamente: puedes descargar y utilizar directamente el modelo E4B principal para obtener las mejores funciones, o el submodelo E2B independiente que ya extrajimos para ti, ofreciendo una inferencia hasta 2 veces más rápida.
2: Tamaños personalizados con combinación y emparejamiento: para un control más detallado adaptado a restricciones de hardware específicas, puedes crear un espectro de modelos de tamaño personalizado entre E2B y E4B utilizando un método que llamamos “combinación y emparejamiento”. Esta técnica te permite cortar con precisión los parámetros del modelo E4B, principalmente ajustando la dimensión oculta de la red de alimentación directa por capa (de 8192 a 16384) y omitiendo selectivamente algunas capas. Estamos lanzando MatFormer Lab, una herramienta que muestra cómo recuperar estos modelos óptimos, que se identificaron al evaluar varias configuraciones en puntos de referencia como MMLU.
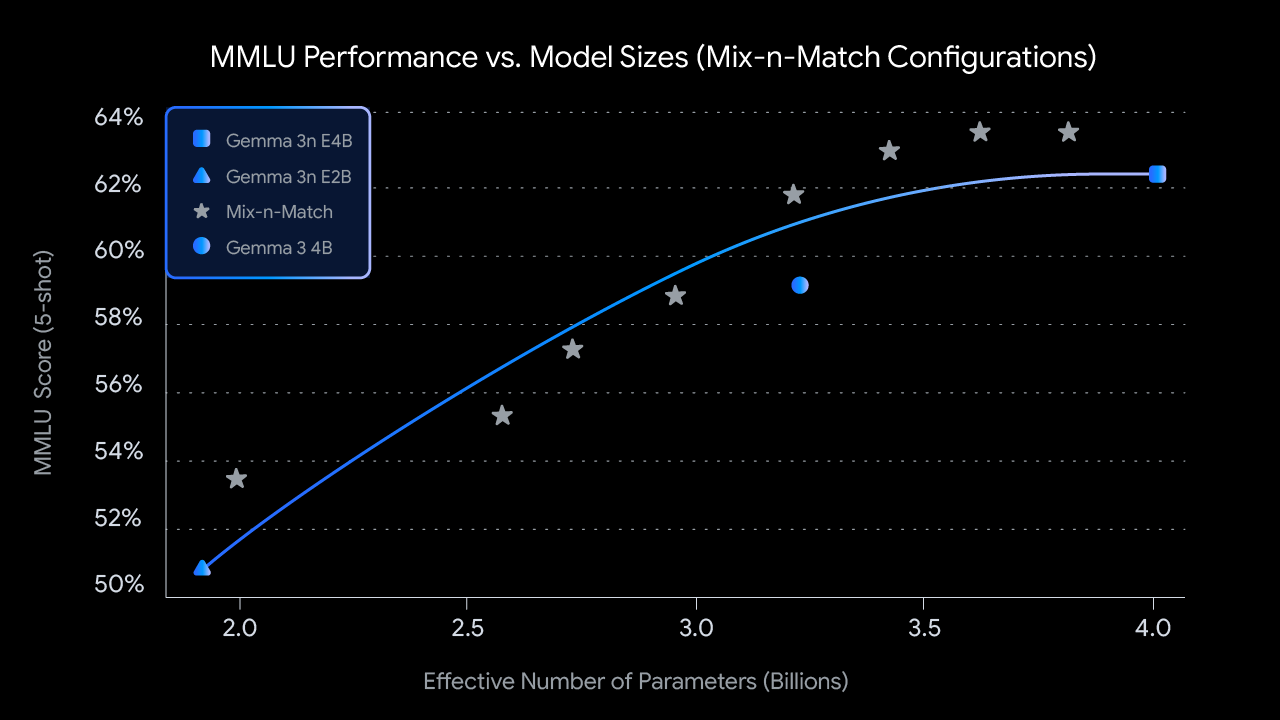
De cara al futuro, la arquitectura de MatFormer también allana el camino para la ejecución elástica. Si bien no forma parte de las implementaciones lanzadas hoy, esta función permite que un solo modelo E4B desplegado cambie dinámicamente entre las rutas de inferencia E4B y E2B sobre la marcha, lo que permite la optimización en tiempo real del rendimiento y el uso de memoria en función de la tarea actual y la carga del dispositivo.
Los modelos de Gemma 3n incorporan inserciones por capa (PLE). Esta innovación está diseñada para la implementación en el dispositivo, ya que mejora drásticamente la calidad del modelo sin aumentar la huella de memoria de alta velocidad requerida en el acelerador de tu dispositivo (GPU/TPU).
Si bien los modelos de Gemma 3n E2B y E4B tienen un recuento total de parámetros de 5B y 8B respectivamente, las PLE permiten que una parte significativa de estos parámetros (las inserciones asociadas con cada capa) se carguen y calculen de manera eficiente en la CPU. Esto significa que solo los pesos del transformador central (aproximadamente 2B para E2B y 4B para E4B) deben asentarse en la memoria del acelerador normalmente más restringida (VRAM).

El procesamiento de entradas largas, como las secuencias derivadas de transmisiones de audio y video, es esencial para muchas aplicaciones multimodales avanzadas en el dispositivo. Gemma 3n presenta el uso compartido de caché KV, una función diseñada para acelerar significativamente el tiempo hasta el primer token para las aplicaciones de respuesta de transmisión.
El uso compartido de caché KV optimiza la forma en que el modelo maneja la etapa de procesamiento de entrada inicial (a menudo llamada fase de “prellenado”). Las claves y los valores de la capa intermedia de la atención local y global se comparten directamente con todas las capas superiores, lo que ofrece una notable mejora al duplicar el rendimiento de prellenado en comparación con Gemma 3 4B. Esto significa que el modelo puede ingerir y comprender secuencias de indicaciones largas mucho más rápido que antes.
Gemma 3n utiliza un codificador de audio avanzado basado en el Universal Speech Model (USM). El codificador genera un token por cada 160 ms de audio (aproximadamente 6 tokens por segundo), que luego se integran como entrada al modelo de lenguaje, proporcionando una representación detallada del contexto de sonido.
Esta capacidad de audio integrada presenta funciones clave para el desarrollo en el dispositivo, entre las que se incluyen:
Observamos resultados particularmente sólidos de AST para la traducción entre inglés y español, francés, italiano y portugués, lo que ofrece un gran potencial para los desarrolladores que desarrollan aplicaciones para dirigirlas a estos idiomas. Para tareas como la traducción del habla, aprovechar las indicaciones de la cadena de pensamiento puede mejorar significativamente los resultados. Aquí tienes un ejemplo:
<bos><start_of_turn>user
Transcribe el siguiente segmento oral en español y tradúcelo al inglés:
<start_of_audio><end_of_turn>
<start_of_turn>modelEn el momento del lanzamiento, el codificador Gemma 3n se implementa para procesar clips de audio de hasta 30 segundos. Sin embargo, esta no es una limitación fundamental. El codificador de audio subyacente es un codificador de transmisión, capaz de procesar audios arbitrariamente largos con entrenamiento adicional de audio de formato largo. Las implementaciones de seguimiento desbloquearán aplicaciones de streaming largas y de baja latencia.
Además de sus capacidades de audio integradas, Gemma 3n presenta un nuevo codificador de visión altamente eficaz, MobileNet-V5-300M, que ofrece un rendimiento de vanguardia para tareas multimodales en dispositivos perimetrales.
Diseñado para ofrecer flexibilidad y potencia en hardware restringido, MobileNet-V5 ofrece a los desarrolladores:
Este nivel de rendimiento se logra con múltiples innovaciones arquitectónicas, entre las que se incluyen:
Beneficiándose de nuevos diseños arquitectónicos y técnicas avanzadas de destilación, MobileNet-V5-300M supera sustancialmente el SoViT de referencia en Gemma 3 (entrenado con SigLip, sin destilación). En un TPU Google Pixel Edge, ofrece una aceleración de 13 veces con cuantificación (6.5 veces sin cuantificación), requiere un 46% menos de parámetros y tiene una huella de memoria 4 veces menor, al mismo tiempo que proporciona una precisión significativamente mayor en las tareas de lenguaje visual
Nos complace compartir más información sobre el trabajo detrás de este modelo. Mantente alerta a nuestro próximo informe técnico de MobileNet-V5, que profundizará en la arquitectura del modelo, las estrategias de escalado de datos y las técnicas avanzadas de destilación.
Hacer que Gemma 3n sea accesible desde el primer día fue una prioridad. Nos enorgullece asociarnos con muchos desarrolladores increíbles de código abierto para garantizar una amplia compatibilidad con herramientas y plataformas populares, incluidas las contribuciones de los equipos detrás de AMD, Axolotl, Docker, Hugging Face, llama.cpp, LMStudio, MLX, NVIDIA, Ollama, RedHat, SGLang, Unsloth y vLLM.
Pero este ecosistema es solo el comienzo. El verdadero poder de esta tecnología está en lo que compilará con ella. Por eso, lanzamos el Gemma 3n Impact Challenge. Tu misión: utilizar las funciones únicas de Gemma 3n en el dispositivo, sin conexión y multimodales para crear un producto para un mundo mejor. Con USD 150,000 en premios, estamos buscando una historia de video convincente y una demostración del factor “wow” que genere un impacto en el mundo real. Únete al desafío y ayuda a crear un futuro mejor.
¿Tienes todo listo para explorar el potencial de Gemma 3n hoy? Te mostramos cómo hacerlo:
Innovación multilingüe en LLM: cómo los modelos abiertos ayudan a resolver la comunicación global

Unlock Gemini’s reasoning: A step-by-step guide to logprobs on Vertex AI

Build with Veo 3, now available in the Gemini API
Simplify your Agent "vibe building" flow with ADK and Gemini CLI

T5Gemma: una nueva colección de modelos Gemma codificadores-decodificadores